Présentation du travail
L’objectif
Depuis 2020, le PRT (Plateau de Recherche Technologique Géomécanique) dispose d’un scanner 3D qui permet de numériser en trois dimensions des objets physiques tels que des échantillons de sols. Ce scanner est utilisé notamment pour capturer les moules en paraffine des échantillons après un test d’érosion par injection d’eau, connu sous le nom de Hole Erosion Test (HET). Ces moules en paraffine représentent l’érosion qui s’est produite à l’intérieur de l’échantillon.
 (Laboratroire Géomécanique, bancs d’essais triaxiaux et perméabilité © S. Nicaise)
(Laboratroire Géomécanique, bancs d’essais triaxiaux et perméabilité © S. Nicaise)
[TODO inserer photo du scanner 3D]
Afin d’effectuer une analyse quantitative des scans obtenus, incluant la mesure des dimensions et du volume, il est essentiel d’utiliser des logiciels adaptés. Dans ce contexte, un programme a déjà été développé au sein du PRT en utilisant le logiciel LabVIEW, permettant d’analyser la morphologie des objets numérisés en 3D et de générer des graphiques en 2D et 3D.
Afin que ce programme puisse être exploité par la communauté scientifique du PRT, il a été nécessaire de le recoder dans un langage de programmation à “accès libre”, comme le langage Python. Cette étape a permis de faciliter l’utilisation et la diffusion de l’outil parmi les chercheurs, contribuant ainsi à l’analyse des scans 3D des moules d’érosion et favorisant les avancées dans le domaine de la géomécanique.
Les outils
 Un gestionnaire de projet ? Trello
Un gestionnaire de projet ? Trello
 Un ide? Visual studio code
Un ide? Visual studio code
 Un gestionnaire de versionnage? git
Un gestionnaire de versionnage? git

Un repo git? ForgeMIA (gitlabà.
 Un logiciel pour design l'interface?, Qt Designer
Un logiciel pour design l'interface?, Qt Designer
 Un hotel ? Trivago
Un hotel ? Trivago
Analyse Morphologique
Etat de l’art
Avant ce commencer on a lister toute les chose a faire, le big cahier des charges, (ou juste une todo list glorifié)
Open: ../../Bordel/Pasted image 20230616140336.png
{kind=link}
Une fois que les tâches à effectuer ont été identifiées, je pouvais enfin me mettre à développer. MAIS PAS SI VITE, avant de commencer à programmer, je dois choisir les bibliotheque que je vais utiliser.
IHM
Pour la bibliothèque de l’IHM, j’avais beaucoup de possibilités. La première était sur la forme que prendrait le programme, je pouvais :
- Faire une application qui tourne dans sa propre fenêtre, dans ce cas j’avais le choix entre plusieurs bibliothèques :
- Tkinter, bibliothèque intégrée à Python qui permet de faire des interfaces simples rapidement.
- Qt, bibliothèque populaire et très documentée avec une grande communauté.
- Faire une application qui tourne dans une page web et là encore j’avais plusieurs choix :
- Faire une Webapp avec Flask, Flask est un serveur web que je connais très bien et le développement d’applications web est une de mes compétences (même si en soi le web n’est pas fun fun).
- Utiliser la bibliothèque mercury qui permet de convertir des notebooks Python en applications web.
Et en sah, il y en avait plein d’autres, tu jettes un coup d’œil sur cette liste et tu pleures.
Finalement, je suis parti sur la première option, les applications web qui tournent dans un navigateur web ont le très gros avantage d’être utilisables sur n’importe quel appareil sans que l’utilisateur ait à installer quoi que ce soit. Mais cette option est très restrictive en ce qui concerne les technologies 3D que je peux utiliser pour mes rendus.
Et je suis parti sur la bibliothèque Qt car tkinter c’est un peu cringe (puis je peux dire ce que je veux a Thomas mais faire des app en Qt c’est pas si mal, je testerais GTK plus tard)
Graphes et rendu 3D
Pour le rendu des graphes, je comptais utiliser la bibliothèque Matplotlib. Elle est très bien documentée et connue dans la communauté des développeurs Python et des chercheurs. Et je sais l’utiliser c’est un bon plus, j’avais commencé à créer des petits scripts qui analysent des fichiers et génèrent des graphes avec Matplotlib :
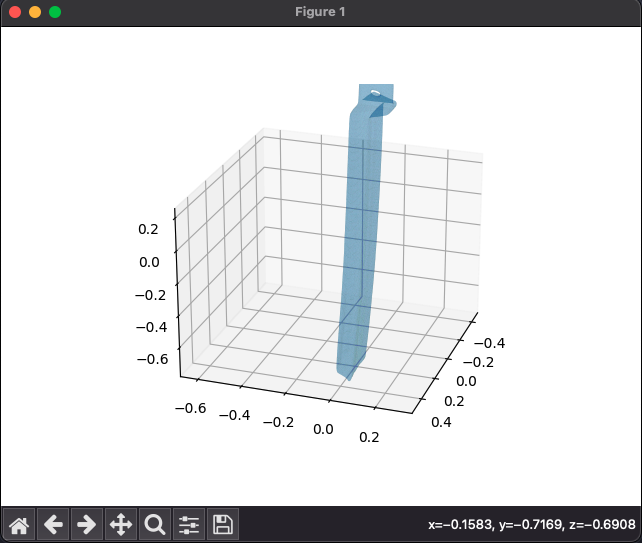
coupe 2D : 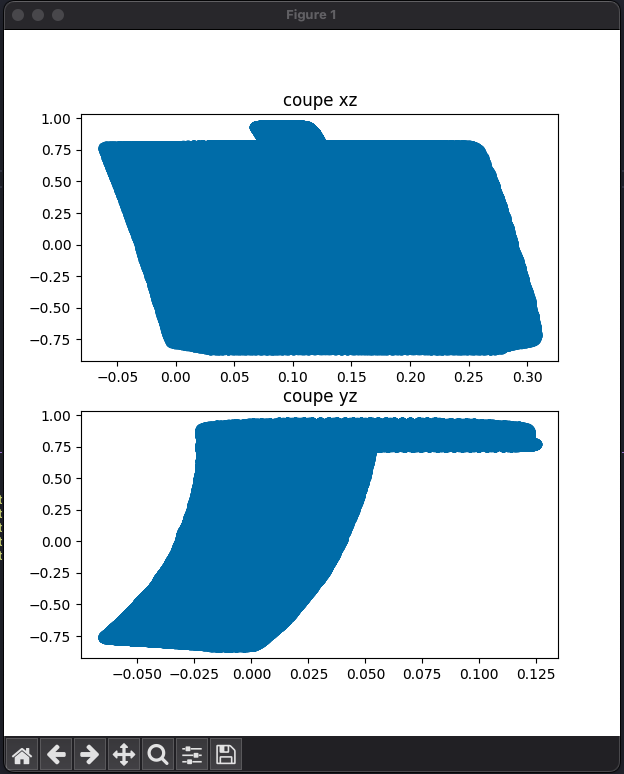 Mesh 3D:
Mesh 3D:
Malheureusement, Matplotlib ne supporte pas l’accélération GPU pour le rendu de ses graphes, ce qui signifie que tout se fait par le processeur. Du coup, avec nos scans 3D a 200k points, les rendus étaient SUPER lents genre revient dans 40 secondes. La seule alternative que j’ai trouvé c’est Vispy, une bibliothèque Python encore en développement qui se veut proche des utilisateurs de Matplotlib, avec des fonctions de haut niveau très similaires, mais aussi proche des développeurs OpenGL avec une API bas niveau. Au début, j’ai un peu galéré à la faire fonctionner comme je le voulais, mais c’était simplement parce que je n’avais pas RTFM. Un fois que j’ai arrêté d’être con c’est allé beaucoup mieux.
Tema ma barettre
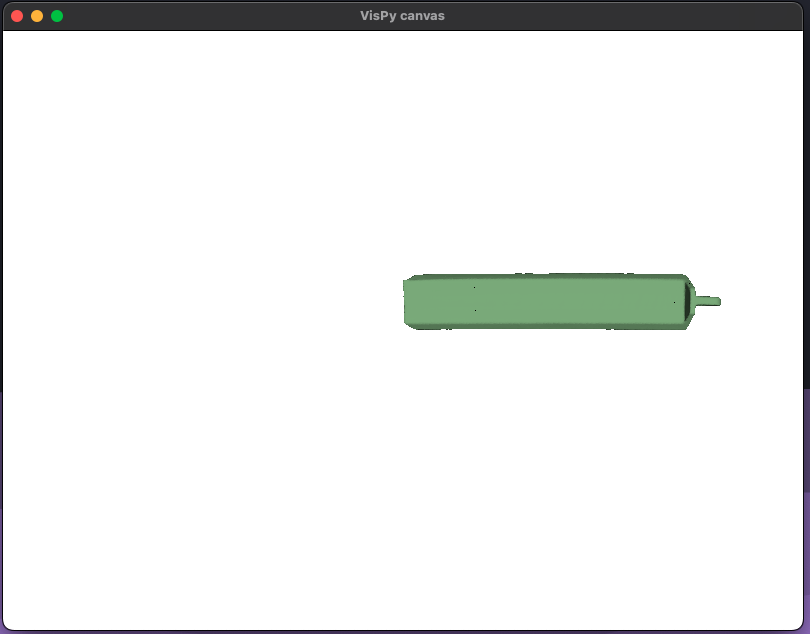 je me suis perdu en chemin
je me suis perdu en chemin
Programmation bien dure
Couche d’abstraction
Une fois les bibliothèques choisies, je pouvais ENFIN (x2) me mettre à programmer pour de vrai. Avant de pouvoir effectuer des calculs, j’avais besoin des fichiers contenant les informations nécessaires, c’est-à-dire les fichiers de scan 3D. Il existe de nombreux formats de fichier permettant de représenter des objets 3D. Afin de simplifier l’interaction de mon programme avec ces différents types de fichiers, j’ai créé une classe appelée ScannedObject. Cette classe abstrait le concept de fichier pour mon programme et se charge de lire et de stocker les données pertinentes disponibles dans les différents formats de fichier.
flowchart TD
A[.stl] --> D
B[.xyz] --> D
C[.obj] --> D(ScannedObject)
D --> E[le reste du programme]
Actuellement la classe ScannedObject supportes 3 types de format de fichier 3D:
-
Le format .obj (Wavefront)) Ce format de fichier est simple à comprendre : chaque ligne correspond à une donnée. Le type de donnée est défini par les caractères au début de la ligne, suivis des valeurs associées à cette donnée. Ce format est utilisé par l’application HP scanner pour fournir les données de scan.
v 0.0 0.0 0.0 v 0.0 0.0 1.0 v 0.0 1.0 0.0 v 0.0 1.0 1.0 v 1.0 0.0 0.0 v 1.0 0.0 1.0 v 1.0 1.0 0.0 v 1.0 1.0 1.0 vn 0.0 0.0 1.0 vn 0.0 0.0 -1.0 vn 0.0 1.0 0.0 vn 0.0 -1.0 0.0 vn 1.0 0.0 0.0 vn -1.0 0.0 0.0 f 1//2 7//2 5//2 f 1//2 3//2 7//2 f 1//6 4//6 3//6 f 1//6 2//6 4//6 f 3//3 8//3 7//3 f 3//3 4//3 8//3 f 5//5 7//5 8//5 f 5//5 8//5 6//5 f 1//4 5//4 6//4 f 1//4 6//4 2//4 f 2//1 6//1 8//1 f 2//1 8//1 4//1 -
Le format .stl Ce format de fichier est légèrement plus complexe que le format .obj, mais reste tout de même très simple à comprendre. Il existe deux types de fichiers STL : les fichiers STL encodés sous forme textuelle (ASCII). Le fichier commence par une ligne qui indique le nom de l’objet. Ensuite, pour chaque triangle constituant le fichier, on trouve les données correspondantes. Enfin, le fichier se termine par un mot-clé spécifique..
solid cube-ascii facet normal 0.000000e+00 0.000000e+00 1.000000e+00 outer loop vertex 0.000000e+00 0.000000e+00 1.000000e+01 vertex 1.000000e+01 0.000000e+00 1.000000e+01 vertex 0.000000e+00 1.000000e+01 1.000000e+01 endloop endfacet facet normal 0.000000e+00 0.000000e+00 1.000000e+00 outer loop vertex 1.000000e+01 1.000000e+01 1.000000e+01 vertex 0.000000e+00 1.000000e+01 1.000000e+01 vertex 1.000000e+01 0.000000e+00 1.000000e+01 endloop endfacet facet normal 1.000000e+00 0.000000e+00 0.000000e+00 outer loop vertex 1.000000e+01 0.000000e+00 1.000000e+01 vertex 1.000000e+01 0.000000e+00 0.000000e+00 vertex 1.000000e+01 1.000000e+01 1.000000e+01 endloop endfacet facet normal 1.000000e+00 0.000000e+00 0.000000e+00 outer loop vertex 1.000000e+01 1.000000e+01 0.000000e+00 vertex 1.000000e+01 1.000000e+01 1.000000e+01 vertex 1.000000e+01 0.000000e+00 0.000000e+00 endloop endfacet facet normal 0.000000e+00 0.000000e+00 -1.000000e+00 outer loop vertex 1.000000e+01 0.000000e+00 0.000000e+00 vertex 0.000000e+00 0.000000e+00 0.000000e+00 vertex 1.000000e+01 1.000000e+01 0.000000e+00 endloop endfacet facet normal 0.000000e+00 0.000000e+00 -1.000000e+00 outer loop vertex 0.000000e+00 1.000000e+01 0.000000e+00 vertex 1.000000e+01 1.000000e+01 0.000000e+00 vertex 0.000000e+00 0.000000e+00 0.000000e+00 endloop endfacet facet normal -1.000000e+00 0.000000e+00 0.000000e+00 outer loop vertex 0.000000e+00 0.000000e+00 0.000000e+00 vertex 0.000000e+00 0.000000e+00 1.000000e+01 vertex 0.000000e+00 1.000000e+01 0.000000e+00 endloop endfacet facet normal -1.000000e+00 0.000000e+00 0.000000e+00 outer loop vertex 0.000000e+00 1.000000e+01 1.000000e+01 vertex 0.000000e+00 1.000000e+01 0.000000e+00 vertex 0.000000e+00 0.000000e+00 1.000000e+01 endloop endfacet facet normal 0.000000e+00 1.000000e+00 0.000000e+00 outer loop vertex 0.000000e+00 1.000000e+01 1.000000e+01 vertex 1.000000e+01 1.000000e+01 1.000000e+01 vertex 0.000000e+00 1.000000e+01 0.000000e+00 endloop endfacet facet normal 0.000000e+00 1.000000e+00 0.000000e+00 outer loop vertex 1.000000e+01 1.000000e+01 0.000000e+00 vertex 0.000000e+00 1.000000e+01 0.000000e+00 vertex 1.000000e+01 1.000000e+01 1.000000e+01 endloop endfacet facet normal 0.000000e+00 -1.000000e+00 0.000000e+00 outer loop vertex 1.000000e+01 0.000000e+00 1.000000e+01 vertex 0.000000e+00 0.000000e+00 1.000000e+01 vertex 1.000000e+01 0.000000e+00 0.000000e+00 endloop endfacet facet normal 0.000000e+00 -1.000000e+00 0.000000e+00 outer loop vertex 0.000000e+00 0.000000e+00 0.000000e+00 vertex 1.000000e+01 0.000000e+00 0.000000e+00 vertex 0.000000e+00 0.000000e+00 1.000000e+01 endloop endfacet endsolidEnsuite, il y a le format .stl encodé de manière binaire, qui est très similaire à sa version textuelle. Il commence par une section d’en-tête de 80 octets, suivi d’un entier (int32) codant le nombre de triangles. Pour chaque triangle, on trouve 12 octets pour le vecteur normal, suivis de 3 fois 12 octets pour les 3 points définissant le triangle. Enfin, il y a 2 octets qui ne servent à rien particulier..
UINT8[80] – Header - 80 bytes UINT32 – Number of triangles - 4 bytes foreach triangle - 50 bytes: REAL32[3] – Normal vector - 12 bytes REAL32[3] – Vertex 1 - 12 bytes REAL32[3] – Vertex 2 - 12 bytes REAL32[3] – Vertex 3 - 12 bytes UINT16 – Attribute byte count - 2 bytes end42 69 6E 61 72 79 20 53 54 4C 20 57 72 69 74 65 72 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0C 00 00 00 00 00 00 00 00 00 00 00 00 00 80 3F 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 3F 00 00 00 3F 00 00 00 00 00 00 00 00 00 00 00 00 80 3F 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 00 00 00 00 00 00 00 00 00 80 3F 00 00 00 BF 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00 00 00 00 00 00 00 00 00 00 00 80 3F 00 00 00 BF 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 BF 00 00 00 00 00 80 00 00 80 3F 00 00 00 00 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00 00 BF 00 00 00 00 00 00 00 00 80 BF 00 00 00 00 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 BF 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 BF 00 00 00 BF 00 00 00 00 00 80 00 00 80 BF 00 00 00 00 00 00 00 3F 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00 00 3F 00 00 00 BF 00 00 00 00 00 00 00 00 80 3F 00 00 00 00 00 00 00 3F 00 00 00 3F 00 00 00 3F 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 BF 00 00 00 00 80 BF 00 00 00 00 00 00 00 00 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00 00 3F 00 00 00 BF 00 00 00 00 80 3F 00 00 00 00 00 00 00 00 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 BF 00 00 00 BF 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 BF 00 00 00 00 80 BF 00 00 00 00 00 00 00 00 00 00 00 3F 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 3F 00 00 00 3F 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00 00 00 80 3F 00 00 00 00 00 00 00 00 00 00 00 3F 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00 00 BF 00 00 00 3F 00 00 00 3F 00 00 00 BF 00 00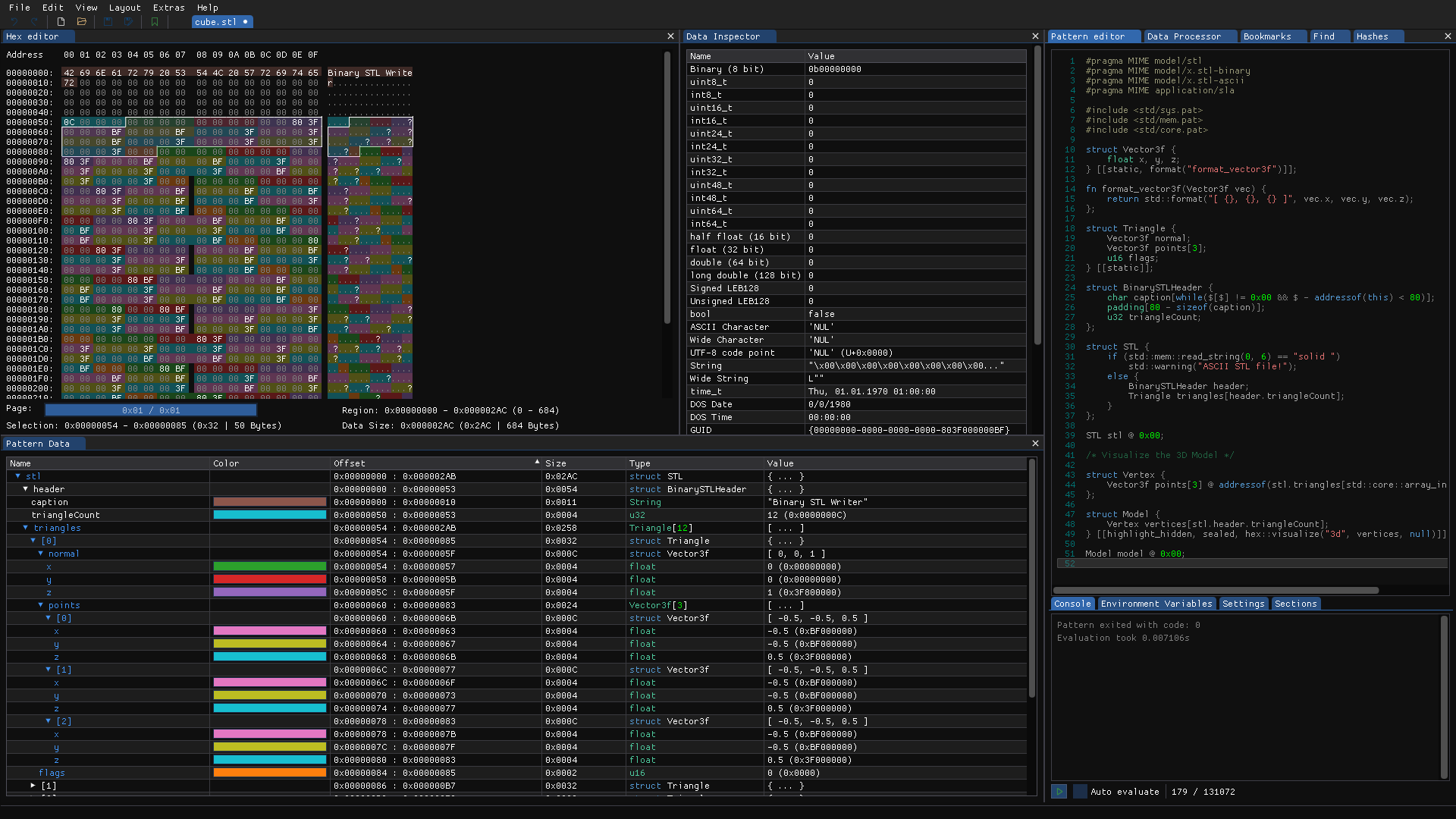
-
Le format de fichier .xyz Le format de fichier XYZ est le format le plus simple actuellement pris en charge, mais il est également le moins bien documenté. Une des spécifications que j’ai trouvées indique que ce format est utilisé par des physiciens pour ). Chaque ligne du fichier correspond à un point dans l’espace et est représenté par ses coordonnées en X, Y et Z.
0.0 0.0 0.0 1.0 0.0 0.0 1.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 1.0 0.0 1.0 1.0 1.0 1.0 0.0 1.0 1.0Le problème avec ce format de fichier est qu’il ne contient pas d’informations sur les faces, ce qui rend impossible le rendu 3D de ces objets. J’ai essayé d’utiliser des algorithmes de triangulation de Matplotlib pour créer des faces à partir des points, mais euuu :
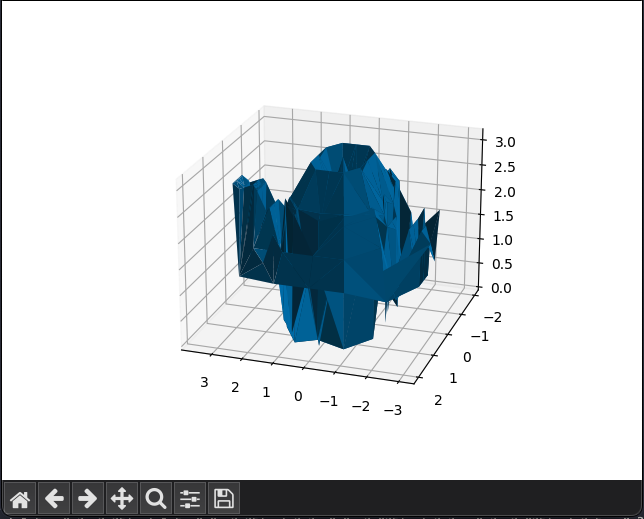 (c’est sensé être la théière btw)
(c’est sensé être la théière btw)
La classe ScannedObject gère également la discrétisation des données. Actuellement, il existe deux méthodes de discrétisation du fichier :
- (Xn;Yn;Zn) Pour Z dans [𝝙n;𝝙n+1] also known as je tranche tout les 𝝙mm et je regarde ce que j’ai dans mes intervalles.
- (Xn;Yn;Zn) tant que Z0-Zi < 𝝙, also known as je veux que mes intervalles fassent au moins 𝝙 de long
Ré-implémentation des calculs de LabView
Maintenant que j’ai mes données dans un format que je maîtrise et que je peux discrétiser, je peux enfin me lancer dans les calculs mathématiques.☝️🤓📐.
J’ai commencé à ré-implémenter toutes les fonctions mathématiques qui étaient dans le programme LabVIEW dans un petit module nommé “math”. J’ai décidé de créer mes propres fonctions et de ne pas passer directement par les fonctions de numpy là où j’en aurais besoin. Ainsi, si je mal comprends un calcul ou si des modifications sont nécessaires, je peux les effectuer à un seul endroit et cela s’appliquera partout. Les fonctions que j’ai ré-implémentées permettent le calcul des données pour générer deux fichiers : un fichier contenant les données pour chaque point de l’objet (dites données brutes) et un fichier contenant les données pour chaque couche discrète (dites données discrètes).
Valeurs calculées pour le fichier de données brutes donc pour chaque point: - angle theta ( 𝜽 ) en radiant - rayon en mm - x - Xmoyen - y - Ymoyen
Valeurs calculées pour le fichier de données discrètes donc pour chaque couche discrete : - Xmoyen - Ymoyen - Zmoyen - Rmoyen - Ecart type omoyen
La manière de calculer ces valeurs sont définit dans l’appendix rédigé par Pierre PHILIPPE le directeur de recherche mais comme je sais que je vais probablement le perdre les voilaaaas.
TODO Explain le detail
| variable | formule |
|---|---|
| rayon ( 𝑟 ) | |
| theta ( 𝜽 ) | |
| Ecart type |
La moyenne étant définit comme
Petit aparté sur 𝜽, car il m’a un peu fait chier.
De 1. Lorsque je voulais tracer le graphe de la “coupe d’une couche”, j’ai remarqué que le calcul de l’angle theta dans le code n’était pas correct. Au lieu d’utiliser la fonction atan, nous devrions utiliser la fonction atan2. L’angle obtenu avec atan est seulement dans l’intervalle [-π/2, π/2]. J’ai découvert ça lorsque je suis passé des coordonnées polaires aux coordonnées cartésiennes.
je fais x = cos(theta) * r y = cos(theta) * r
je plot le tout et voila ce que j’ai
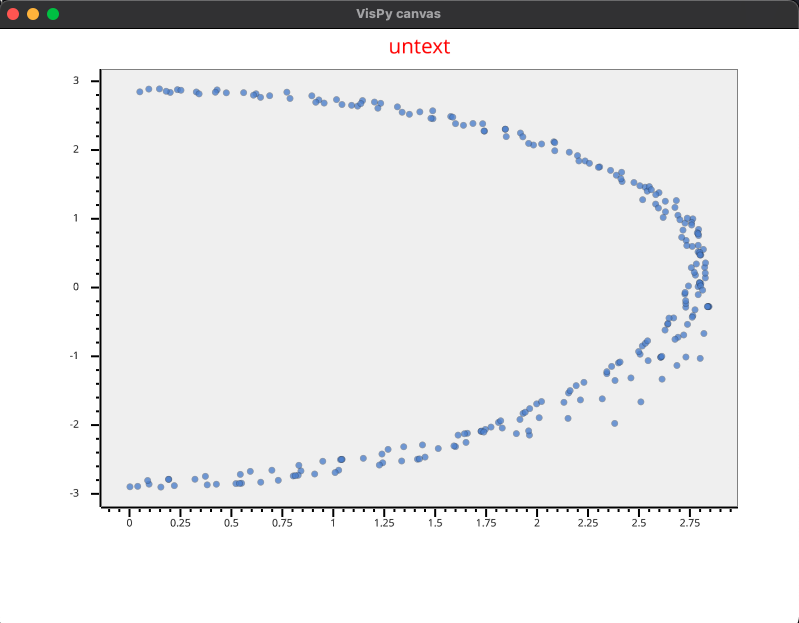
si on utilise atan2 au lieu d’atan, on a exactement ce que l’on cherche :
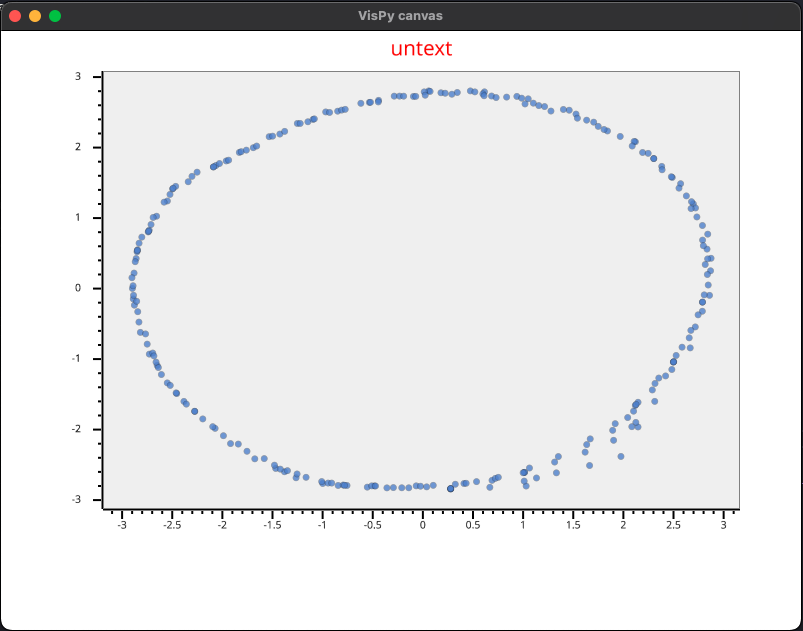
Mais c’est pas fini ! Fwahahah! Sinon, ce serait trop simple. Voici la coupe de la même couche, mais cette fois directement à partir des coordonnées x et y du fichier :
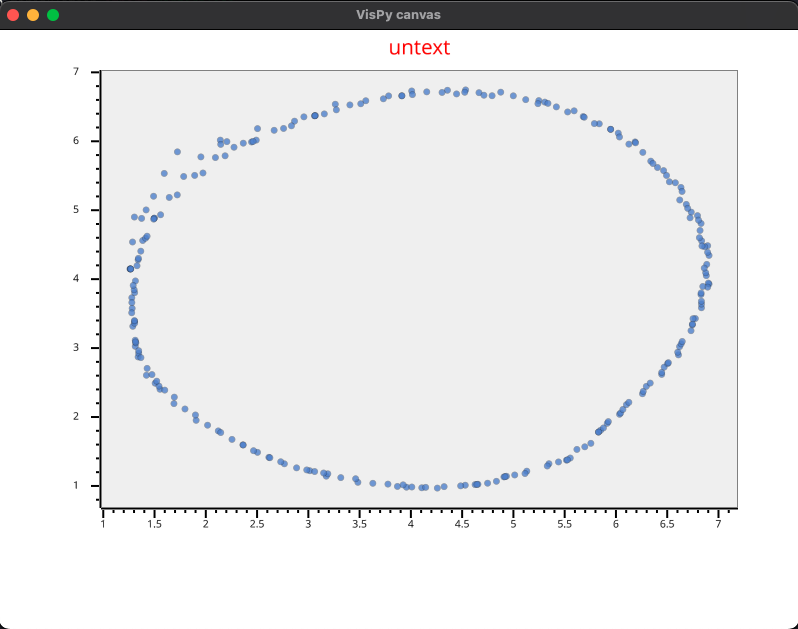
Tu vois clairement que les valeurs sont inversées sur l’axe X ainsi que sur l’axe Y. C’est dû à la définition de thêta dans l’appendix. Pour obtenir exactement les mêmes points, on devrait utiliser la formule suivante : thêta = . Cette définition, trouvée sur Internet, ne provoque pas d’inversion des angles. Actuellement, aucun de ces deux points n’est corrigé, car on veut se rapprocher du comportement du programme LabVIEW. Il a été décidé de ne pas y apporter de modification.
Output files
🅱️on maintenant il faut aligner tout ces calculs et foutre leurs résultats dans un fichier.
Les fonctions qui permettent de calculer les données brutes ou discrétisées sont dans le module utils.data_procressing, ils sont très straight forward, tu leur passe un objet 3D, tu leurs donne le nombre de décimales après la virgule, ton DeltaZ et dans les 3 seconde t’as un dictionnaire avec ce que tu cherche
(clefs du dictionnaire des données brutes)
colones = ["X (en mm)",
"Y (en mm)",
"Z (en mm)",
"theta (en rad)",
"rayon (en mm)",
"Xi-Xmoy",
"Yi-Ymoy"](clefs du dico des données discrètes)
colones = ["X moy (en mm)",
"Y moy (en mm)",
"Z moy (en mm)",
"Discretisation(en mm)",
"Rayon moyen (en mm)",
"Rayon ecart type (en mm)"]Lourd on a nos données maintenant faut les save dans un fichier, mais comme on est pas des barbares on va formater les données. Dans le module utils.files.output on a toute les fonctions qui dictent comment doit être les fichiers de sorties, on y retrouve la fonction format_data(data:dict, separator:str, selected_columns:list = None) -> str:,
Comme la signature de la fonction nous de dit si bien, cette fonction prends un dictionnaire (très précisément un dict[str:list]), un séparateur de colonne et une liste de string, cette liste de string permet de définir quels colonnes prendre et dans quel ordre, si on donne pas cette liste la fonction va juste lire les clefs du dict dans l’ordre ou il les trouves.
(fichier données brutes)
X (en mm) Y (en mm) Z (en mm) theta (en rad) rayon (en mm) Xi-Xmoy Yi-Ymoy
3.517216 0.468406 0.0 0.901878 4.05448 3.180711 2.514336
[...](fichier données discrètes)
X moy (en mm) Y moy (en mm) Z moy (en mm) Discretisation(en mm) Rayon moyen (en mm) Rayon ecart type (en mm)
0.336505 -2.045929 0.527324 0.999584 6.127587 2.355418
[...]Dans ce module on trouve aussi la petite fonction qui met des entête aux fichiers de sorties, et en vrai les méta-données je crache souvent dessus mais c’est grave useful.
##############################
Analyse Morphologique
version :1.2.2
filename : exemple.obj
date : 07/06/2023 10:32:11
discretisation : Z0-Zi < DeltaZ
delta_z : 1.0
had been veticalised : yes
##############################Pile 10 ligne, facile a ignorer, tout est bon.
Redressement
Anyway, les fonctionnalités de base du programme LabView sont la, on peut faire la partie la plus compliquée du stage, le redressement de l’objet. C’est ce que pensait Djalim du passé jusqu’à qu’il tombe sur le Mega super ultra script de Jérôme DURIEZ qui aligne les axes d’inertie d’un objet 3D avec les axes de l’espaces, j’ai absolument pas compris ce que je viens de dire et c’est très proche a de la magie noire.
 Me and the boys when we align the principal axes of rotation of the mesh with the coordinate axes (we love casting spells).
Me and the boys when we align the principal axes of rotation of the mesh with the coordinate axes (we love casting spells).
Donc oui le script de Jérôme fait très bien sont travail moi je suis juste venu faire une rotation de π/2 sur ce que sort le programme. Oui je suis une fraude je sais 😎 mais règle 2.

Code original car je pourrais pas le refaire
def transfStl(stlFileName):
import numpy,time
import stl
stlMesh = stl.mesh.Mesh.from_file(stlFileName+'.stl')
volume, cog, inertia = stlMesh.get_mass_properties()
[val,vect] = numpy.linalg.eig(inertia)
if numpy.linalg.det(vect) < 0:
vect[:,2] = - vect[:,2]
rot = vect.T
for fIdx in range(len(stlMesh.vectors)):
for vIdx in range(3):
stlMesh.vectors[fIdx][vIdx] = rot@(stlMesh.vectors[fIdx][vIdx] - cog)
stlMesh.save(stlFileName+'Transf.stl')Mais je comprends ce qui se passe :
- On récupère le centre de gravité de l’objet ainsi que sa matrice d’inertie.
- On calcule le vecteur propre de la matrice d’inertie.
- On multiplie tous les vertices de l’objet par le vecteur propre moins le centre de gravité.
- ???
- Enjoy!
Création de l’interface graphique
Conception avec Qt Designer
Anyway, on a tout ce qu’il faut ou il faut, on peut assembler tout ça dans une interface très homme très machine. Du coup comme dit précédemment j’utilise la bibliophilique Qt et le logiciel QtDesigner.
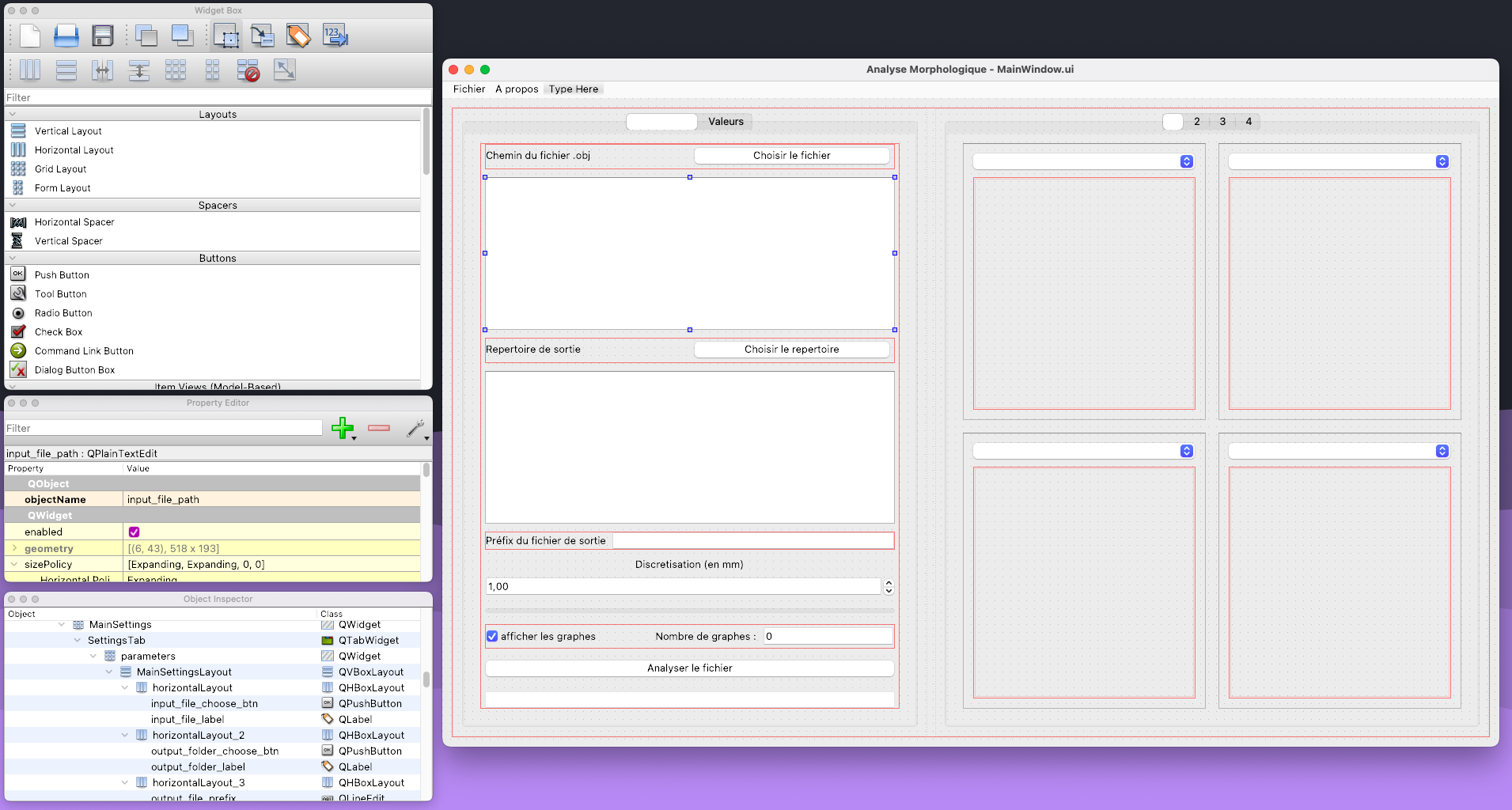
QtDesigner me permet de créer des interfaces en “drag and dropant” des éléments graphiques dans la fenêtre qui représente l’application, je peux ensuite exporter la fenêtre dans un fichier .ui que je convertit en suite en fichier .py qui contient une classe qui contient tout les éléments graphiques. Dans un autre fichier, j’importe cette classe et je crée une autre classe qui hérite de la première. C’est ainsi que j’ajoute le code à la partie interface.
# UI_MainWindow.py
class Ui_MainWindow(object):
def setupUi(self, MainWindow):
MainWindow.setObjectName("MainWindow")
MainWindow.resize(1336, 842)
self.centralwidget = QtWidgets.QWidget(MainWindow)
self.centralwidget.setObjectName("centralwidget")
self.gridLayout = QtWidgets.QGridLayout(self.centralwidget)
self.gridLayout.setObjectName("gridLayout")
self.horizontalLayout_4 = QtWidgets.QHBoxLayout()
self.horizontalLayout_4.setObjectName("horizontalLayout_4")
self.MainSettings = QtWidgets.QWidget(self.centralwidget)
self.MainSettings.setEnabled(True)
self.MainSettings.setMinimumSize(QtCore.QSize(600, 794))
self.MainSettings.setMaximumSize(QtCore.QSize(600, 16777215))
self.MainSettings.setObjectName("MainSettings")
[...]
# MainWindow.py
class MainWindow(QtWidgets.QMainWindow, Ui_MainWindow):
def __init__(self, parent=None):
super(MainWindow, self).__init__(parent)
self.setupUi(self)
[...]Liaison au code et threading
OK, donc là on a du code dans une fenêtre, c’est cool. Il suffit simplement d’importer les fonctions qui créent nos deux fichiers, les appeler dans MainWindow.py et écrire la sortie dans un fichier, non ? ET BIEN NON. Parce que si tu fais les calculs dans MainWindow.py, ils seront exécutés sur le thread principal, le même qui gère la boucle d’événements de l’affichage. Donc, lorsque tu mets tes gros calculs dans le thread principal, ton event loop passe de à ça :
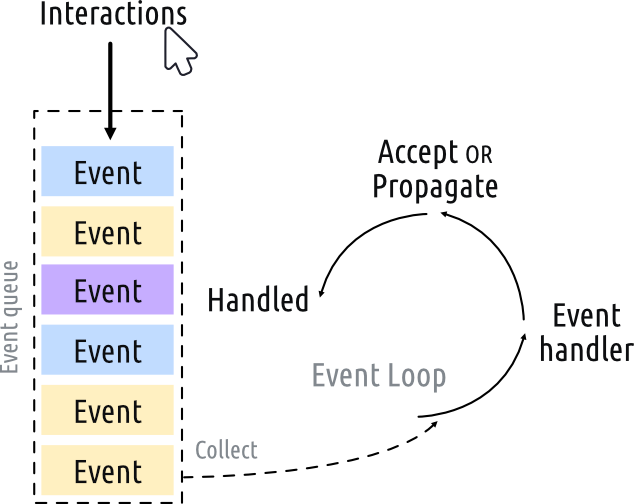 a ça
a ça
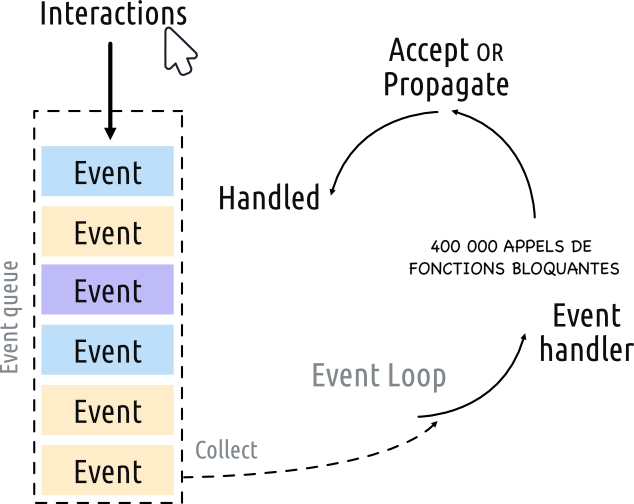
Et donc, lorsque tu lances ton calcul, ton programme se bloque. En fait, il ne se bloque pas réellement, mais le système considère qu’il est bloqué car tu ne traites aucun événement pendant que tu effectues tous tes calculs. Et tu as BEAUCOUP de calculs à effectuer.

Du coup la solution c’est de déléguer la lourde tache de faire les calculs a un autre Thread qui ne servira qu’a ça, et pourquoi s’arrêter a un seul thread, créons en pour chaque tache pour paralléliser et donc accélérer un max le programme. (Du coup oui je crée pas des thread par choix mais pas nécessité)
Du coup je me documente, et je crée des Workers qui héritent de ma petite classe Worker trop mignonne.
"""
Created on Wed Apr 26 2023
@name: Worker.py
@desc: Base class for the workers
@auth: Djalim Simaila
@e-mail: djalim.simaila@inrae.fr
"""
from PyQt5.QtCore import pyqtSignal, QObject
class Worker(QObject):
"""
Base class for the workers
:param name: The name of the worker
:ivar name: The name of the worker
:ivar progress_value: The current progress value
:ivar progress_weight: The weight of the progress bar
:ivar finished: The signal to emit when the worker is finished
:ivar progress: The signal to emit the progress value
:ivar status: The signal to emit the status of the worker
"""
finished = pyqtSignal()
progress = pyqtSignal(int)
status = pyqtSignal(str)
def __init__(self,name:str):
super().__init__()
self.name = name
self.progress_value = 0
self.progress_weight = 100
def set_status(self, status:str):
"""
Set the weight of the progress bar
"""
self.status.emit(f"[{self.name}]: {status}")
def set_weight(self, weight):
"""
Set the weight of the progress bar
"""
self.progress_weight = weight
def update_progress(self, percent):
"""
Update the progress bar
"""
self.progress_value += int(percent/100*self.progress_weight)
self.progress.emit(self.progress_value)De base devait il y avoir que trois Workers (PreProcessWorker, RawDataWorker, DiscreteDataWorker), mais du fin fond du néant distordu vient l’apparition du programme “Origin”, qui parse et traite les fichiers que le programme LabView sort. Bah go intégrer ça dans mon programme.
Du coup je crée une nouvelle fonction dans le module data_processing , la fonction get_advanced_data(discrete_data:dict, raw_data:dict, V_scan = 0,)->dict:.
Comme le dit si bien la signature de la fonction, elle prends en paramètre les données brutes et discrétisées et les utilise pour renvoyer nos ”𝓘𝓷𝓭𝓲𝓬𝓪𝓽𝓮𝓾𝓻𝓼 𝓜𝓸𝓻𝓹𝓱𝓸𝓵𝓸𝓰𝓲𝓺𝓾𝓮𝓼” (“Indicateurs morphologiques” si l’appareil a pas une font cursive issou) dans un dictionnaire.
Et bam, on lui donne son propre Worker et c’est bon. Il y a eu un peu de sauce quand il a fallu l’intégrer, car il a besoin des données des deux autres threads. Actuellement, le Worker se déclenche lorsque le nombre de tâches terminées est égal à 2. À l’avenir, je créerai des flags pour chaque tâche, et il se déclenchera lorsque les deux flags liés aux threads dont il dépend seront à True. Ces données ne sont pas automatiquement exportées dans un fichier, car l’utilisateur doit fournir une variable () pour le calcul de certains indicateurs. Donc, c’est à l’utilisateur de les exporter dans un fichier en utilisant le bouton dédié après avoir fourni la variable.

Et je crées de donc un Worker pour chaque tache:
- PreProcessWorker
Il lit le chemin de fichier donné par l’utilisateur, il crée une instance de
ScannedObject, il redresse (si demandé), il normalise et il discrétise pour que les deux autres aient pas a le faire. (les deux autres en questions) - RawDataWorker
Il prends un
ScannedObject, et il calcule les données brutes dont on a parlé précédemment et les écrits dans un fichier. - DiscreteDataWorker
Il prend un
ScannedObjecten paramètre et calcule les données discrètes dont nous avons parlé précédemment, puis les écrit dans un fichier. - AdvancedDataWorker Il prend les dictionnaires sortis par les deux Workers précédents, calcule les indicateurs morphologiques, puis les stocke dans la classe de la fenêtre principale.
Et voilà, les tâches sont parallélisées, donc plus de blocage dans le thread principal.
Fun fact, si tu ne conserves pas de référence vers le thread ou le worker, le garbage collector de Python peut supprimer les objets avant même qu’ils aient le temps de se lancer. Lol.
Petit flow chart
flowchart TD
A(app.py)-- calls --> B(MainWindow.py)
B -- event loop--> B
B -- calls in a thread --> C(PreProcessWorker.py)
C -- When finished, triggers and calls in a thread --> D(RawDataWorker.py)
C -- When finished, triggers and calls in a thread --> E(DiscreteDataWorker.py)
D -- Stores results in --> B
D --> G(Save result in a file)
E -- Stores results in --> B
E --> G
D -- When finished increment counter --> F
E -- When finished increment counter --> F(Wait for both task to be finished)
F -- Trigger in a thread --> H(AdvancedDataWorker.py)
H -- Stores results in --> B
Oui, les appels vont dans tout les sens c’est un bordel sans nom mais ca marche et c’est le plus opti pour l’instant

Si on regarde la meme chose sous forme de gantt ca fait moins peur
gantt
dateFormat HH:mm:ss
section A
App.py - calls to MainWindow.py : 00:00:00, 00:00:01
section B
MainWindow.py - event loop : 00:00:01, 00:00:30
section C
PreProcessWorker.py : 00:00:01, 00:00:16
section D
RawDataWorker.py : 00:00:16, 00:00:21
RawDataWorker.py - saves result in a file : 00:00:21, 00:00:22
RawDataWorker.py - increments counter F : 00:00:22, 00:00:23
section E
DiscreteDataWorker.py : 00:00:16, 00:00:24
DiscreteDataWorker.py - saves result in a file : 00:00:24, 00:00:25
DiscreteDataWorker.py - increments counter F : 00:00:25, 00:00:26
section F
MainWindow.py(finishedTaskCounter) - waits for both tasks to be finished : 00:00:01, 00:00:26
triggers in a thread to AdvancedDataWorker.py : 00:00:26, 00:00:27
section H
AdvancedDataWorker.py : 00:00:27, 00:00:30Et comme les indicateurs morphologiques je les sort pas de mon cul et toujours du parfait appendix de Pierre voici le tableau d’avant mais complet UwU :
| variable | formule |
|---|---|
| rayon ( 𝑟 ) | |
| theta ( 𝜽 ) | |
| Ecart type (σ) | |
| longueur ( 𝑙 ) | |
| longueur ( 𝐿 ) | |
| tortuosité ( 𝑇 ) | |
| surface ( 𝑆 ) | |
| dispersion totale () | |
| rayon hydraulique (Rₕ) | |
| 𝐻𝐼 |
Bon y’a bien deux variable que je sort de mon cul, c’est 𝑙 et 𝐿, (Mais tout vient de l’appendix donc tout va bien)

Dans l’appendix il est écrit que 𝐿 est la distance entre la première couche et la dernière couche. I aint no mathematician, mais je me souvient que la distance entre deux points dans l’espace c’est :
(n c’est le nombre de couche)
Quant a 𝑙, il est écrit :
I aint no mathematician, mais ce moi je comprends, c’est que je fais la somme des distance entre chaque couches, donc juste :
Graphes
Bon, les fichiers textes, c’est cool, mais le programme LabVIEW avait des graphiques, donc le mien doit en avoir aussi. Les graphiques, ce n’était pas compliqué. Vispy peut exporter les QWidgets qui contiennent son rendu, donc j’ai utilisé Vispy pour tous les graphiques. Les premiers graphiques sont ceux qui étaient présents dans le programme LabVIEW, plus un rendu 3D en temps réel. - Coupe XZ - Coupe YZ - Évolution du rayon moyen - Évolution de la différence entre la moyenne des rayons et les rayons moyens - Mesh 3D - Coupe d’une couche - Évolution du rayon de chaque point d’une couche en fonction de theta
Contrairement à tous les calculs, c’est le main thread qui effectue le rendu des graphiques, c’est pourquoi le programme hang pendant environ 0,5 seconde lorsque l’utilisateur sélectionne un graphique. Cest dû au fait que je ne peux pas transférer des QWidgets entre les threads, donc pour l’instant, je suis obligé de faire le rendu dans le main thread. De plus, comme je ne sais pas comment faire des choix, j’ai mis en place un système de placement modulable qui permet à l’utilisateur de placer les graphiques comme il le souhaite.
Gestion des paramètres
Pour la gestion des paramètres, j’ai pris la décision de renier mon humanité, de rejeter tout respect envers l’art du code, et d’utiliser le design pattern très controversé du Singleton.

J’ai créé une classe SettingManager qui gère les paramètres du programme, ainsi que la persistance de certaines données entre les lancements. Pour permettre à tous les threads d’accéder à ces paramètres, la classe SettingManager stocke la première instance créée et la renvoie via la fonction statique get_instance(). Avec du recul, je pense qu’il y a une marge d’amélioration, par exemple, pourquoi ne pas rendre toutes les méthodes statiques au lieu de passer par une instance ? De plus, le fait de passer par une instance unique peut ne pas garantir l’écriture des paramètres dans le fichier en toute sécurité thread-safe. L’utilisation d’un mutex pourrait être utile à cet égard. Les paramètres sauvegardés par le programme sont les suivants :
- La manière de discrétiser.
- S’il faut verticaliser ou non le fichier en entrée.
- Le suffixe des fichiers de sortie.
- La position des derniers graphes utilisés.
- S’il faut aligner les colonnes dans les fichiers de sortie.
- L’extension de fichier des fichiers de sortie.
- Le séparateur des fichiers de sortie.
- S’il faut ajouter ou non l’en-tête aux fichiers de sortie.
Documentation
Et comme je suis un programmeur de qualité, j’ai écrit des docstrings pour TOUT LE CODE. Tout le code est documenté, mais cette documentation est super chiante à accéder : t’imagine devoir cloner le repo et faire Ctrl+Shift+F pour trouver de la doc ? Chiant ! Heureusement, tu vas être content car la documentation du code est disponible sur mon site perso, et dans le repo, car je n’ai pas encore trouvé comment faire des GitLab Pages avec ForgeMia. Une partie de cette documentation a été écrite manuellement, et le reste a été généré grâce aux docstrings présents dans le code, tout ça fait avec le programme Sphinx, un programme de documentation pour Python.
Validation des calculs
Ok now everything is good… or is it? (v sause music starts playing). Les premières versions du programme sortaient des résultats différents de ceux du programme LabView. Et je t’entends Jean Pierre : “Différents a quel point”, me demandes-tu ? Eh bien, I’m glad you fucking asked, car j’ai justement fait des scripts pour mesurer les différences.
On va juste regarder la barette car sinon on a trop de données.
En partant du fichier .obj on avait ça :
Time to calculate raw data: 3.5996789932250977
Analyse données brutes :
diff moyenne de x : 0.0128
diff moyenne de y : 0.003967
diff moyenne de z : 1e-06
diff moyenne de t : 2.328187
diff moyenne de r : 0.231564
diff moyenne de xmoy : 0.296167
diff moyenne de ymoy : 0.091834
diff gloabale des fichiers : 0.4235028571428571
Voir check_raw_data_full.txt pour plus de détails
Voir check_raw_data_minimal.txt pour les différences significatives
____________________________________________________________________
Time to calculate discrete data: 0.6473770141601562
Analyse données discretisées:
difference moyenne X: 0.155527
difference moyenne Y: 0.064374
difference moyenne Z: 0.28113
difference moyenne R: 0.128454
difference moyenne STD: 0.050681
diff globale des fichiers: 0.13603320000000002
Voir check_discrete_data_full.txt pour plus de détails
Voir check_discrete_data_minimal.txt pour les différences significatives
_________________________________________________________________________And i dont know bout you but je pense qu’il y a de grosses différences, mais ce qui me turlupine le plus, ce sont les différences sur les données brutes pour X, Y et Z. Genre, tu ne fais que lire ce que tu vois, mais ce n’est pas la même chose ? Ensuite, je me souviens que le programme LabView prend en entrée un fichier .xyz, alors allons faire pareil et voyons ce que ça donne.
Analyse données brutes :
diff moyenne de x : 0.0
diff moyenne de y : 0.0
diff moyenne de z : 0.0
diff moyenne de t : 1.627337
diff moyenne de r : 0.22678
diff moyenne de xmoy : 0.284644
diff moyenne de ymoy : 0.088124
diff gloabale des fichiers : 0.3181264285714286
____________________________________________________________________________
Analyse données discretisées:
difference moyenne X: 0.155527
difference moyenne Y: 0.064374
difference moyenne Z: 0.281129
difference moyenne R: 0.128454
difference moyenne STD: 0.05068
diff globale des fichiers: 0.13603280000000004
Tiens tiens tiens, les differences sur x,y et z ont disparus, ce qui veux dire deux chose: - Mon programme sait lire (cool) - Passer d’un fichier .obj a .xyz change beaucoup les valeurs?
Le deuxième point est bizarre, donc je mène l’enquête et oui, le passage par un .xyz par MeshLab arrondit très légèrement la dernière décimale, pourquoi avons-nous de si grosses différences? Je ne sais pas et je n’avais pas de raisons de chercher plus loin.
Ok, pour le reste des données brutes, on verra plus tard, maintenant qu’on a la même source que LabView, allons faire des mathématiques ☝️🤓. Les données discrètes sont très différentes, ce qui est bizarre pour les moyennes de X, Y et Z vu qu’on fait une moyenne des mêmes points, sauf si… on ne fait pas la moyenne des mêmes points?? Maintenant, je suis sûr que j’ai exactement les mêmes points que Labview en partant des fichiers .xyz. Le seul endroit où ça peut foirer, c’est la discrétisation, allons vérifier ça.
Voici la première ligne du fichier de LabVIEW pour les données discrétisées de la barrette :
Xmoy (mm) Ymoy (mm) Zmoy (mm) rayon moyen (mm) rayon ecart type (mm)
15,109002 -1,126580 0,525629 6,530663 3,607419Cette ligne nous dit que la moyenne des X qui ont un Z compris entre 0 et 1 est de 15,109002. Du coup, je fais un peu d’ingénierie inversé. Je veux savoir où le programme LabView a coupé son tableau sans pouvoir consulter le code. Je sais que, par exemple, “15,109002” est la moyenne de X à partir du premier jusqu’à un point dont je ne connais pas la position, mais puisque j’ai tous les points, je peux faire du « brute-forcing » : je calcule la moyenne de tous les points à partir du premier jusqu’à ce que je trouve la moyenne de 15,109002.
et la bim badabim badaboum
line position : 616 |should have stoped : 1 position higherLe programme LabView prend un point en trop, je me dis, “ah, bah je fais probablement un tour de boucle en moins, j’ajoute un tour de boucle arbitraire”.
(extrait du fichier de différences entre mes résultats et ceux de références)
0: X: 0.0 Y: 0.0 Z: 0.0 R: 0.0 [...]
1: X: 0.019978 Y: 0.002066 Z: 0.000777 R: 0.009135 [...]Ok donc la première intervalle est bonne maintenant, mais pas la seconde? le comportement est pas régulier?
Je modifie mon script pour qu’il continue de brute force les autres moyennes et oh boy
line position : 616 |should have stoped : 1 position higher
line position : 1257 |should have stoped : 2 position higher
line position : 1981 |should have stoped : 3 position higher
line position : 2730 |should have stoped : 11 position higher
line position : 3554 |should have stoped : 6 position higher
line position : 4436 |should have stoped : 11 position higher
line position : 5236 |should have stoped : 13 position higher
line position : 5894 |should have stoped : 12 position higher
line position : 6540 |should have stoped : 10 position higher
line position : 7188 |should have stoped : 14 position higher
line position : 7842 |should have stoped : 14 position higher
line position : 8491 |should have stoped : 23 position higher
line position : 9155 |should have stoped : 19 position higher
line position : 9808 |should have stoped : 28 position higher
line position : 10461 |should have stoped : 26 position higher
line position : 11121 |should have stoped : 28 position higher
line position : 11779 |should have stoped : 28 position higher
[...]Le comportement est pas régulier. Je cherche un paterne genre le nombre d’élément dans chaque intervalles
nb of element in z0 to z1: 616
nb of element in z1 to z2: 641
nb of element in z2 to z3: 724
nb of element in z3 to z4: 749
nb of element in z4 to z5: 824
nb of element in z5 to z6: 882
nb of element in z6 to z7: 800
nb of element in z7 to z8: 658
nb of element in z8 to z9: 646
nb of element in z9 to z10: 648
nb of element in z10 to z11: 654
nb of element in z11 to z12: 649Mais je comprends pas d’ou vient cette différence majeure.
Vref, les fichiers de labview comme reference c’est cool mais ya grave moyen de faire mieux, et Alexis a grave fait mieux, il a fait le EXCEL DE RÉFÉRENCE et la, on peut voir super rapidement ou, qui et quoi a merdé, super useful.
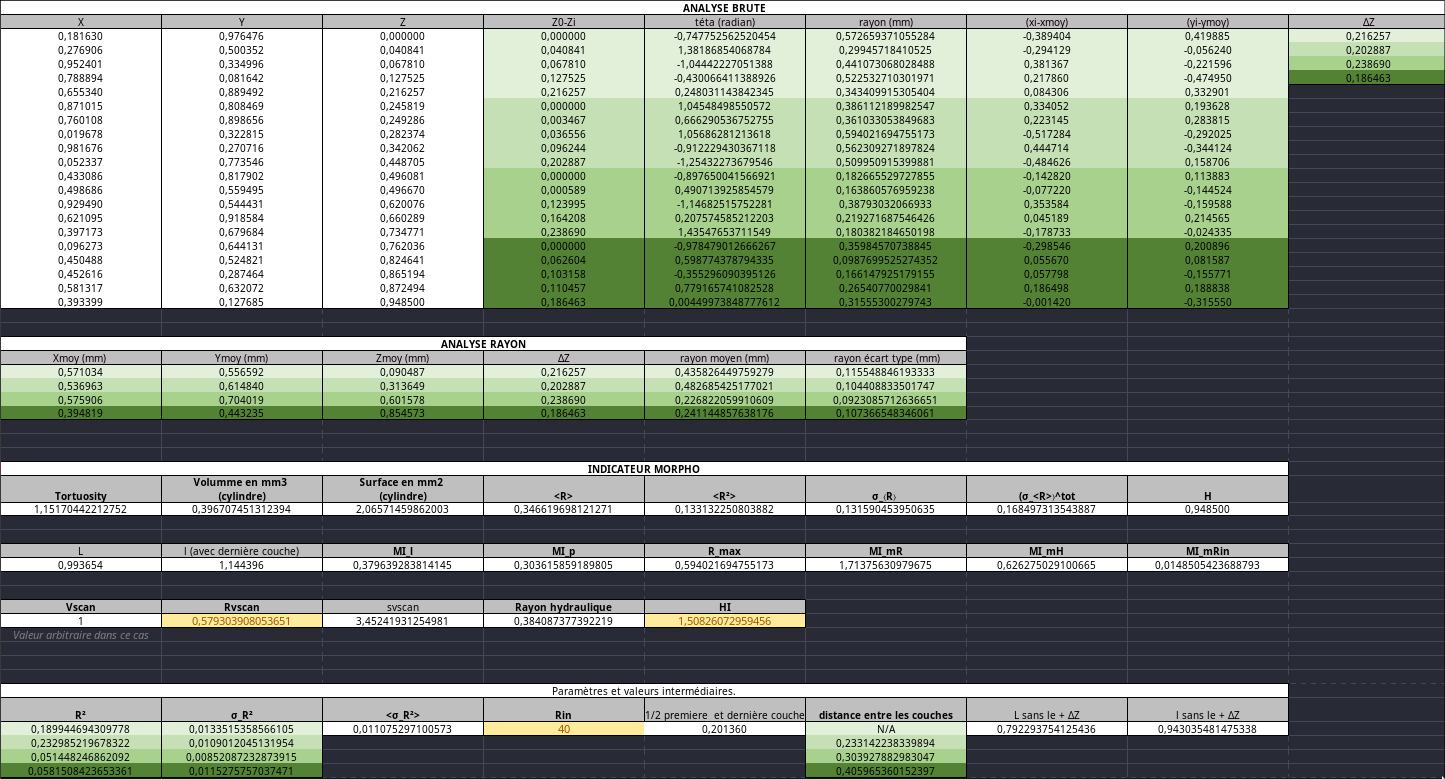
Ducoup long story short je sais pas lire et je faisait pas le bon ecart type mais une fois que ca a ete iddentifé hop hop hop on change 5 ligne de code et on passe de ca
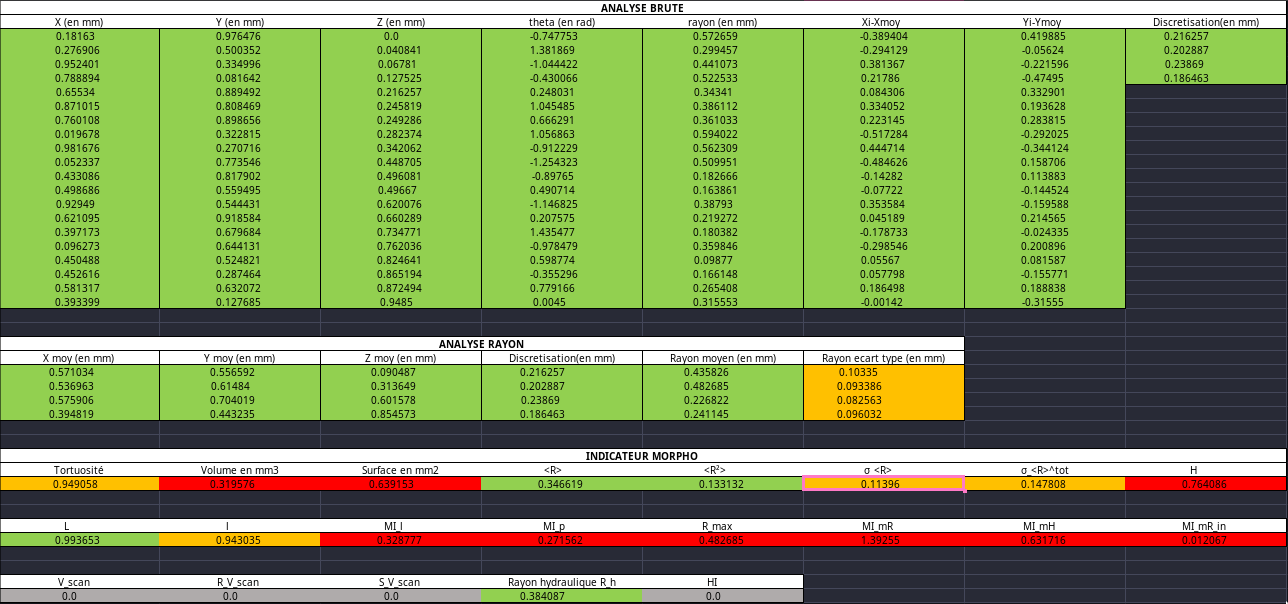
Ou mis a part l’écart type, ya que les indicateurs morphologiques qui sont vachement meh (c’est la version 1.2.0), bah maintenant on a ca dans la version 1.2.2.
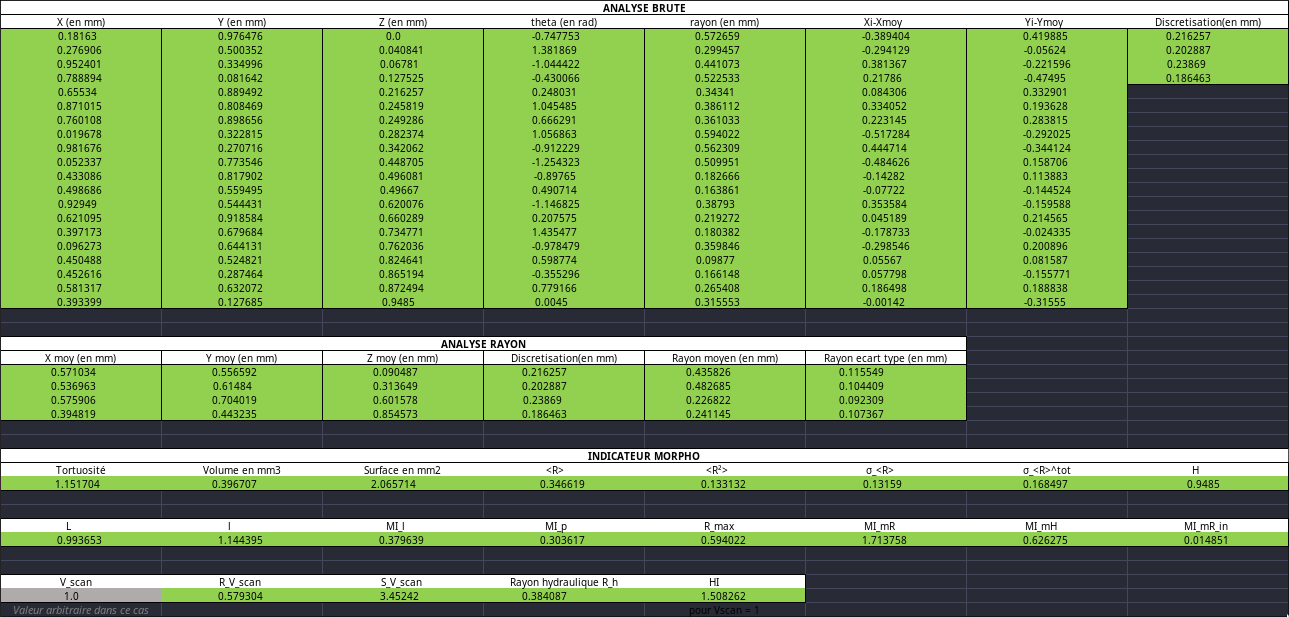
Tout est vert, c’est très joli et surtout ça marque la fin du boulot que j’ai à faire. Je pourrais très facilement mettre en place une CI/CD GitLab maintenant que nous avons un fichier de référence et même un site en production. Cela automatiserait les tests pour les développeurs ainsi que le déploiement du site web de documentation, mais je n’ai pas assez de temps. Je peux également générer des exécutables et des installateurs. Je pense que je vais très probablement faire ça.
Height Calculator (Bonus)
Ce projet avait pas de nom du coup je l’ai baptisé Height Calculator, pas tres poussé mais au moins tu sais ce que tu recois.
CONTEXTE
Mon second maitre de stage, a une suite de 3 scripts qui permettait de mesurer le niveau de l’eau a partir d’une camera. Le principe est simple, dans nos essais de surverse, on place une camera et un fond de couleur sur le coté de l’ecoullement, on a donc un contrate entre l’eau et le fond, si on a garde que la ligne ou l’eau finit et le fond de couleur commence on a une jolie liste de coordonées X,Y, avec ces coordonnées on fait une regression polynomiale et on a une fonction qui deffinit notre hauteur d’eau en pixel, on prends le Y pour X = le milleu de la zone de scan et on le multiplies par un coefficient pixel to centimetres.
Pour faire tout ca il y avait 3 programmes :
- un qui permet a l’utilsateur de crop la video en input et qui export les coordonées de crop dans un fichier.
- un qui petmet l’utilisateur de calibrer les paramettre HSV pour faire ressortir le contraste eau/fond de couleur et qui exporte les paramettre dans un fichier
- Le dernier programme, ou l’utilisateur doit lire le contenu des deux precedants fichier et modifier le code pour inserer les paramettres pour faire tout ce que j’ai dit dans le gros pavé plus haut mais ducoup le code des deux premier scipt est present dans celui la (car il doit refaire les meme opertations).
Du coup moi mon taff c’est prendre ces 3 scripte et en faire un programme qui fait tout de A a Z. Du fait qu’on a donné une deadline de genre une semaine donc 5 jours, j’ai renier tout les principe de clean code, documentation et autre concepte cools, j’ai juste pissé du code mais c’est tres fun car j’adore pisser du code.
Etant donné que j’avais le code original et que j’avais pas beacoup de temps j’ai essayé un truc un peu chelou, j’ai simplifier les entrée et sorties des 3 programme et je les ai foutus dans des thread qui realisent tous une tache a partir des entrée sorties simplifiés, chaque thread sauf le premier a un buffer de qui permet ,s’il est trop lent, de ne pas skipper des frames qu’il recoivent via des signaux. L’avantage de cette architecture c’est que chaque operation est faite une fois (et pas deux fois comme dans la precedente implementation) et surtout pendant qu’un des thread est occupé, un autre thread peut preparer l’input de l’autre thread (pratique).
InputVideoThead Ce thread de la fraude sert à lire un flux vidéo quel qu’il soit et à envoyer des frames aux autres threads à intervalles réguliers. Bien que je considère ce thread comme un peu inutile, il a la lourde tâche de donner la cadence du traitement des images : les autres threads ont pour but de faire leur travail le plus vite possible, du coup s’ils reçoivent 1678 frames en une seconde et que le double arrive la seconde d’après, ton PC explose car tu n’as plus de RAM en 3 secondes. Du coup, l’InputVideoThead attend un peu, genre 42 ms (soit 1000ms divisé par 24 images), avant de donner une autre frame aux autres threads. Et oui, comme dit précédemment, elle abstrait le concept de vidéo : on peut lui donner une vidéo, comme une caméra en input et le reste du programme n’a aucune idée d’où vient la frame qu’ils sont en train de traiter de qui permet (dans la limite ou le pc qui le fait tourner ne date pas de 2003) un traitement en temps réel. Du coup, ce thread renvoie via un signal à intervalles réguliers une frame d’un flux vidéo.
ColorCalibrationThread Ce thread prend en input une frame sortie par l’InputVideoThread et y applique des filtres HSV, on a donc une image en noir et blanc ou le blanc represente les elements dont le contraste ,par rapport au fond, est elevé. Mais le probleme c’est qu’un image est rarement parfaite, on a des petite “taches” qui viennent parasiter notre image, ducoup pour les supprimer on errode notre image, mais l’errode retire des informations sur la ligne qui separe l’eau du fond, pour retrouver ces information on dilate par derriere. Une fois l’erode et le dilate fait ce thread renvoie via un signal une frame en noir et blanc ou inshallah le fond est noir et l’eau est blanche.
MesureThread
C’est dans ce thread que toute la magie opere, elle prends la frame renvoyé par le ColorCalibrationThread et parcours l’image pixel par pixel , et python il aime pas ca, basiquement python est trop lent pour scanner 307200 pixel (640x480) en moins de 42ms.
 Mais du coup, comment je fais ? Initialement, je voulais mettre du code en C dans le code Python : le C est un langage bas niveau qui passe pas par des interpréteurs chelous, donc ça va vite, mais après deux recherches on m’a dit que c’est une solution de boomer, le C étant vieux et les “djeuns” utilisant Numba, et ils ont raison, Numba permet de compiler du Python en JIT (Just In Time, c’est-à-dire uniquement quand on en a besoin), la seule contrainte étant que le code doit être très “orienté numérique”, c’est deux jolis mots pour dire que tu fais beaucoup de mathématiques et que t’as beaucoup de boucles. Et dans notre cas, c’est un peu des deux. Donc, j’utilise Numba pour traiter nos frames, et ça va vraiment beaucoup plus vite : le programme peut désormais traiter de la 720p à 60 fps, soit 55 296 000 frames par seconde (on peut probablement aller plus haut, mais ça n’a pas été demandé, donc osef).
Et donc j’utilise aussi Numba pour calculer nos régressions, le niveau de la régression pouvant monter jusqu’à, euuh, beaucoup. Et je lui demande de calculer 640 points dans les mêmes 42 ms.
Mais du coup, comment je fais ? Initialement, je voulais mettre du code en C dans le code Python : le C est un langage bas niveau qui passe pas par des interpréteurs chelous, donc ça va vite, mais après deux recherches on m’a dit que c’est une solution de boomer, le C étant vieux et les “djeuns” utilisant Numba, et ils ont raison, Numba permet de compiler du Python en JIT (Just In Time, c’est-à-dire uniquement quand on en a besoin), la seule contrainte étant que le code doit être très “orienté numérique”, c’est deux jolis mots pour dire que tu fais beaucoup de mathématiques et que t’as beaucoup de boucles. Et dans notre cas, c’est un peu des deux. Donc, j’utilise Numba pour traiter nos frames, et ça va vraiment beaucoup plus vite : le programme peut désormais traiter de la 720p à 60 fps, soit 55 296 000 frames par seconde (on peut probablement aller plus haut, mais ça n’a pas été demandé, donc osef).
Et donc j’utilise aussi Numba pour calculer nos régressions, le niveau de la régression pouvant monter jusqu’à, euuh, beaucoup. Et je lui demande de calculer 640 points dans les mêmes 42 ms.
 (tema la gueule du truc, mnt remplace “n” par genre 5)
Anyway, on va chercher au milieu de la courbe de la régression pour le Y qui représente la hauteur d’eau en pixel ; cette hauteur, on la multiplie par un coefficient pixel-cm et on envoie ça via un signal et hop, notre programme est fini.
(tema la gueule du truc, mnt remplace “n” par genre 5)
Anyway, on va chercher au milieu de la courbe de la régression pour le Y qui représente la hauteur d’eau en pixel ; cette hauteur, on la multiplie par un coefficient pixel-cm et on envoie ça via un signal et hop, notre programme est fini.
Les plus attentifs ont capté que dans tout ca, l’utilisateur il pas grand chose a dire, et c’est le cas, ces 3 thread peuvent etre 100% autonome et faire le truc sans utilisateur ( a partir du moment ou ils ont un flux video en entrée), pour redonner la souveraineté du programe a l’utilisateur, je lui donne l’access au cerveau des 3 thread, ce que j’ai omis de dire c’est que pour faire leur taches, les thread cherchent des valeurs dans un dictionnaire de paramètres qui ressemble a ça :
self.parametters = {
"hue_min":0,
"hue_max":180,
"sat_min":0,
"sat_max":255,
"val_min":0,
"val_max":255,
"min_x":0,
"max_x":640,
"min_y":0,
"max_y":480,
"fps":24,
"scale_x":100,
"scale_y":100,
"kernel_size": 3,
"iterations": 2,
"coeff": 0.5,
"regression_degree": 1,
"video_frame_rate": 24,
}Et c’est par le biais de l’interface graphique que l’utilisateur influe sur ces paramètres, mais comme tu es très attentif et que tu as des compétences en threading, tu vas me dire : “Mais Djalim, si l’utilisateur modifie les paramètres pendant que les threads les lisent, comment peux-tu être sûr que les modifications des paramètres ont été prises en compte ? Ce n’est pas THREAD SAFE !” Et tu as tout à fait raison, tu mérites une étoile pour ton attention ! Pour rendre le programme thread safe et éviter des comportements étranges comme un PYTHON QUI SEGFAULT PAR EXEMPLE,
 tu dois ajouter des mutex un peu partout. Un mutex est une structure de données qui permet de contrôler l’accès concurrent à des ressources partagées. Tu peux imaginer cela comme un bâton de parole, mais pour les variables. Si tu as besoin de lire ou de modifier la variable, attends que le bâton de parole soit libre. Ainsi, lorsque l’utilisateur modifie un paramètre, cela envoie un signal dans chaque thread qui attend que le mutex soit libre dans chaque thread (oui car chaque thread a une copie des paramètres) et dès qu’il est libre, il modifie les paramètres et le relâche ensuite. Et voilà, c’est thread safe !
tu dois ajouter des mutex un peu partout. Un mutex est une structure de données qui permet de contrôler l’accès concurrent à des ressources partagées. Tu peux imaginer cela comme un bâton de parole, mais pour les variables. Si tu as besoin de lire ou de modifier la variable, attends que le bâton de parole soit libre. Ainsi, lorsque l’utilisateur modifie un paramètre, cela envoie un signal dans chaque thread qui attend que le mutex soit libre dans chaque thread (oui car chaque thread a une copie des paramètres) et dès qu’il est libre, il modifie les paramètres et le relâche ensuite. Et voilà, c’est thread safe !
Du coup l’utilisateur peut influer sur les paramètres HSV, la zone ou le traitement doit avoir lieu, le niveau de la régression et plein d’autres truc fun que tu peux voir dans ce screen.
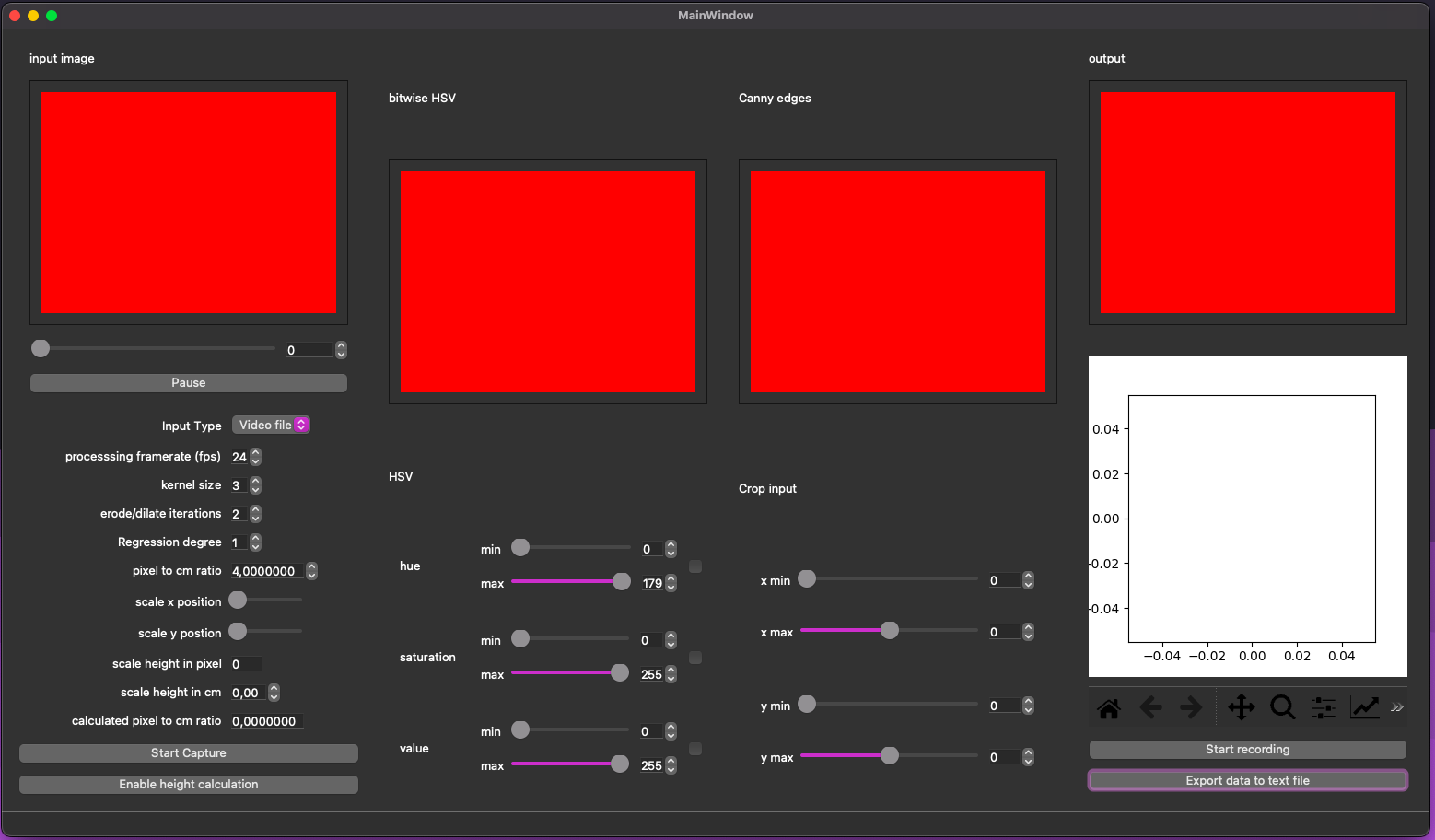
Et oui, le MesureThread n’envoie pas la hauteur pour chaque frame, sinon on aurait 24 valeurs par seconde, ce qui serait chiant; il prend juste une hauteur toutes les secondes. Basiquement, si le numéro de la frame est divisible par les FPS, il envoie la hauteur à notre joli graphe Matplotlib et on peut exporter les valeurs dans un petit CSV avec deux colonnes: « t (en s) » et « h (en cm) ».